DoWhy-The Causal Story Behind Hotel Booking Cancellations

We consider the problem of estimating what impact does assigning a room different to what a customer had reserved has on the booking cancellation.
The gold standard of finding this out would be to use experiments such as Randomized Controlled Trials wherein each customer is randomly assigned to one of the two categories i.e. each customer is either assigned a different room or the same room as he had booked before.
But what if we cannot intervene or its too costly too peform such an experiment (Ex- The Hotel would start losing its reputation if people learn that its randomly assigning people to different rooms). Can we somehow answer our query using only observational data or data that has been collected in the past?
[1]:
#!pip install dowhy
import dowhy
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import logging
logging.getLogger("dowhy").setLevel(logging.INFO)
[2]:
dataset = pd.read_csv('https://raw.githubusercontent.com/Sid-darthvader/DoWhy-The-Causal-Story-Behind-Hotel-Booking-Cancellations/master/hotel_bookings.csv')
dataset.head()
[2]:
| hotel | is_canceled | lead_time | arrival_date_year | arrival_date_month | arrival_date_week_number | arrival_date_day_of_month | stays_in_weekend_nights | stays_in_week_nights | adults | ... | deposit_type | agent | company | days_in_waiting_list | customer_type | adr | required_car_parking_spaces | total_of_special_requests | reservation_status | reservation_status_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Resort Hotel | 0 | 342 | 2015 | July | 27 | 1 | 0 | 0 | 2 | ... | No Deposit | NaN | NaN | 0 | Transient | 0.0 | 0 | 0 | Check-Out | 2015-07-01 |
| 1 | Resort Hotel | 0 | 737 | 2015 | July | 27 | 1 | 0 | 0 | 2 | ... | No Deposit | NaN | NaN | 0 | Transient | 0.0 | 0 | 0 | Check-Out | 2015-07-01 |
| 2 | Resort Hotel | 0 | 7 | 2015 | July | 27 | 1 | 0 | 1 | 1 | ... | No Deposit | NaN | NaN | 0 | Transient | 75.0 | 0 | 0 | Check-Out | 2015-07-02 |
| 3 | Resort Hotel | 0 | 13 | 2015 | July | 27 | 1 | 0 | 1 | 1 | ... | No Deposit | 304.0 | NaN | 0 | Transient | 75.0 | 0 | 0 | Check-Out | 2015-07-02 |
| 4 | Resort Hotel | 0 | 14 | 2015 | July | 27 | 1 | 0 | 2 | 2 | ... | No Deposit | 240.0 | NaN | 0 | Transient | 98.0 | 0 | 1 | Check-Out | 2015-07-03 |
5 rows × 32 columns
[3]:
dataset.columns
[3]:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'stays_in_weekend_nights',
'stays_in_week_nights', 'adults', 'children', 'babies', 'meal',
'country', 'market_segment', 'distribution_channel',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'reserved_room_type',
'assigned_room_type', 'booking_changes', 'deposit_type', 'agent',
'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date'],
dtype='object')
Data Description
For a quick glance of the features and their descriptions the reader is referred here. https://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-02-11/readme.md
Feature Engineering
Lets create some new and meaningful features so as to reduce the dimensionality of the dataset. The following features have been created:- - Total Stay = stays_in_weekend_nights + stays_in_week_nights - Guests = adults + children + babies - Different_room_assigned = 1 if reserved_room_type & assigned_room_type are different, 0 otherwise.
[4]:
# Total stay in nights
dataset['total_stay'] = dataset['stays_in_week_nights']+dataset['stays_in_weekend_nights']
# Total number of guests
dataset['guests'] = dataset['adults']+dataset['children'] +dataset['babies']
# Creating the different_room_assigned feature
dataset['different_room_assigned']=0
slice_indices =dataset['reserved_room_type']!=dataset['assigned_room_type']
dataset.loc[slice_indices,'different_room_assigned']=1
# Deleting older features
dataset = dataset.drop(['stays_in_week_nights','stays_in_weekend_nights','adults','children','babies'
,'reserved_room_type','assigned_room_type'],axis=1)
dataset.columns
[4]:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'meal', 'country', 'market_segment',
'distribution_channel', 'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'booking_changes', 'deposit_type',
'agent', 'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date', 'total_stay', 'guests',
'different_room_assigned'],
dtype='object')
[5]:
dataset.isnull().sum() # Country,Agent,Company contain 488,16340,112593 missing entries
dataset = dataset.drop(['agent','company'],axis=1)
# Replacing missing countries with most freqently occuring countries
dataset['country']= dataset['country'].fillna(dataset['country'].mode()[0])
[6]:
dataset = dataset.drop(['reservation_status','reservation_status_date','arrival_date_day_of_month'],axis=1)
dataset = dataset.drop(['arrival_date_year'],axis=1)
[7]:
# Replacing 1 by True and 0 by False for the experiment and outcome variables
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(1,True)
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(0,False)
dataset['is_canceled']= dataset['is_canceled'].replace(1,True)
dataset['is_canceled']= dataset['is_canceled'].replace(0,False)
dataset.dropna(inplace=True)
dataset.head()
[7]:
| hotel | is_canceled | lead_time | arrival_date_month | arrival_date_week_number | meal | country | market_segment | distribution_channel | is_repeated_guest | ... | booking_changes | deposit_type | days_in_waiting_list | customer_type | adr | required_car_parking_spaces | total_of_special_requests | total_stay | guests | different_room_assigned | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Resort Hotel | False | 342 | July | 27 | BB | PRT | Direct | Direct | 0 | ... | 3 | No Deposit | 0 | Transient | 0.0 | 0 | 0 | 0 | 2.0 | False |
| 1 | Resort Hotel | False | 737 | July | 27 | BB | PRT | Direct | Direct | 0 | ... | 4 | No Deposit | 0 | Transient | 0.0 | 0 | 0 | 0 | 2.0 | False |
| 2 | Resort Hotel | False | 7 | July | 27 | BB | GBR | Direct | Direct | 0 | ... | 0 | No Deposit | 0 | Transient | 75.0 | 0 | 0 | 1 | 1.0 | True |
| 3 | Resort Hotel | False | 13 | July | 27 | BB | GBR | Corporate | Corporate | 0 | ... | 0 | No Deposit | 0 | Transient | 75.0 | 0 | 0 | 1 | 1.0 | False |
| 4 | Resort Hotel | False | 14 | July | 27 | BB | GBR | Online TA | TA/TO | 0 | ... | 0 | No Deposit | 0 | Transient | 98.0 | 0 | 1 | 2 | 2.0 | False |
5 rows × 22 columns
[30]:
dataset_copy = dataset.copy(deep=True)
Calculating Expected Counts
Since the number of number of cancellations and the number of times a different room was assigned is heavily imbalanced, we first choose 1000 observations at random to see that in how many cases do the variables; ‘is_cancelled’ & ‘different_room_assigned’ attain the same values. This whole process is then repeated 10000 times and the expected count turns out to be 51.8% which is almost 50% (i.e. the probability of these two variables attaining the same value at random). So statistically speaking, we have no definite conclusion at this stage. Thus assigning rooms different to what a customer had reserved during his booking earlier, may or may not lead to him/her cancelling that booking.
[9]:
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset.sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
[9]:
We now consider the scenario when there were no booking changes and recalculate the expected count.
[10]:
# Expected Count when there are no booking changes = 49.2%
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]==0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
[10]:
In the 2nd case, we take the scenario when there were booking changes(>0) and recalculate the expected count.
[11]:
# Expected Count when there are booking changes = 66.4%
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]>0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
[11]:
There is definitely some change happening when the number of booking changes are non-zero. So it gives us a hint that Booking Changes must be a confounding variable.
But is Booking Changes the only confounding variable? What if there were some unobserved confounders, regarding which we have no information(feature) present in our dataset. Would we still be able to make the same claims as before?
Enter DoWhy
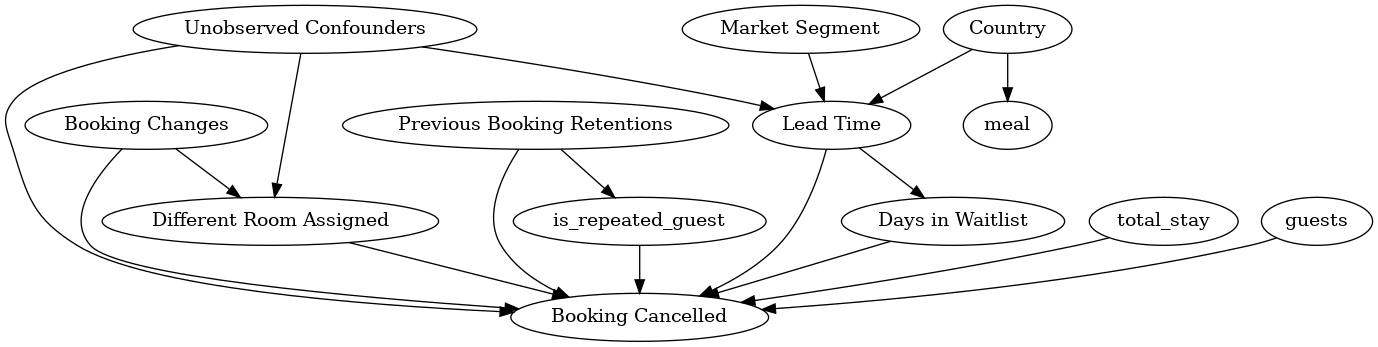
Step-1. Create a Causal Graph
Represent your prior knowledge about the predictive modelling problem as a CI graph using assumptions. Don’t worry, you need not specify the full graph at this stage. Even a partial graph would be enough and the rest can be figured out by DoWhy ;-)
Here are a list of assumptions that have then been translated into a Causal Diagram:-
Market Segment has 2 levels, “TA” refers to the “Travel Agents” and “TO” means “Tour Operators” so it should affect the Lead Time (which is simply the number of days between booking and arrival).
Country would also play a role in deciding whether a person books early or not (hence more Lead Time) and what type of Meal a person would prefer.
Lead Time would definitely affected the number of Days in Waitlist (There are lesser chances of finding a reservation if you’re booking late). Additionally, higher Lead Times can also lead to Cancellations.
The number of Days in Waitlist, the Total Stay in nights and the number of Guests might affect whether the booking is cancelled or retained.
Previous Booking Retentions would affect whether a customer is a Repeated Guest or not. Additionally, both of these variables would affect whether the booking get cancelled or not (Ex- A customer who has retained his past 5 bookings in the past has a higher chance of retaining this one also. Similarly a person who has been cancelling this booking has a higher chance of repeating the same).
Booking Changes would affect whether the customer is assigned a different room or not which might also lead to cancellation.
Finally, the number of Booking Changes being the only confounder affecting Treatment and Outcome is highly unlikely and its possible that there might be some Unobsevered Confounders, regarding which we have no information being captured in our data.
[12]:
import pygraphviz
causal_graph = """digraph {
different_room_assigned[label="Different Room Assigned"];
is_canceled[label="Booking Cancelled"];
booking_changes[label="Booking Changes"];
previous_bookings_not_canceled[label="Previous Booking Retentions"];
days_in_waiting_list[label="Days in Waitlist"];
lead_time[label="Lead Time"];
market_segment[label="Market Segment"];
country[label="Country"];
U[label="Unobserved Confounders"];
is_repeated_guest;
total_stay;
guests;
meal;
market_segment -> lead_time;
lead_time->is_canceled; country -> lead_time;
different_room_assigned -> is_canceled;
U -> different_room_assigned; U -> lead_time; U -> is_canceled;
country->meal;
lead_time -> days_in_waiting_list;
days_in_waiting_list ->is_canceled;
previous_bookings_not_canceled -> is_canceled;
previous_bookings_not_canceled -> is_repeated_guest;
is_repeated_guest -> is_canceled;
total_stay -> is_canceled;
guests -> is_canceled;
booking_changes -> different_room_assigned; booking_changes -> is_canceled;
}"""
Here the Treatment is assigning the same type of room reserved by the customer during Booking. Outcome would be whether the booking was cancelled or not. Common Causes represent the variables that according to us have a causal affect on both Outcome and Treatment. As per our causal assumptions, the 2 variables satisfying this criteria are Booking Changes and the Unobserved Confounders. So if we are not specifying the graph explicitly (Not Recommended!), one can also provide these as parameters in the function mentioned below.
[13]:
model= dowhy.CausalModel(
data = dataset,
graph=causal_graph.replace("\n", " "),
treatment='different_room_assigned',
outcome='is_canceled')
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
INFO:dowhy.causal_model:Model to find the causal effect of treatment ['different_room_assigned'] on outcome ['is_canceled']
Step-2. Identify the Causal Effect
We say that Treatment causes Outcome if changing Treatment leads to a change in Outcome keeping everything else constant. Thus in this step, by using properties of the causal graph, we identify the causal effect to be estimated
[14]:
#Identify the causal effect
identified_estimand = model.identify_effect()
print(identified_estimand)
WARNING:dowhy.causal_identifier:If this is observed data (not from a randomized experiment), there might always be missing confounders. Causal effect cannot be identified perfectly.
WARN: Do you want to continue by ignoring any unobserved confounders? (use proceed_when_unidentifiable=True to disable this prompt) [y/n] y
INFO:dowhy.causal_identifier:Instrumental variables for treatment and outcome:[]
INFO:dowhy.causal_identifier:Frontdoor variables for treatment and outcome:[]
Estimand type: nonparametric-ate
### Estimand : 1
Estimand name: backdoor1
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes))
d[different_room_assigned]
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes)
### Estimand : 2
Estimand name: backdoor2
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes)
### Estimand : 3
Estimand name: backdoor3
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes)
### Estimand : 4
Estimand name: backdoor4
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes)
### Estimand : 5
Estimand name: backdoor5
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes)
### Estimand : 6
Estimand name: backdoor6
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay)
### Estimand : 7
Estimand name: backdoor7
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,d
d[different_room_assigned]
ays_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list)
### Estimand : 8
Estimand name: backdoor8
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,m
d[different_room_assigned]
eal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,meal)
### Estimand : 9
Estimand name: backdoor9
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,g
d[different_room_assigned]
uests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,guests)
### Estimand : 10
Estimand name: backdoor10
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes)
### Estimand : 11
Estimand name: backdoor11
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes)
### Estimand : 12
Estimand name: backdoor12
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes)
### Estimand : 13
Estimand name: backdoor13
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay)
### Estimand : 14
Estimand name: backdoor14
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list)
### Estimand : 15
Estimand name: backdoor15
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,meal)
### Estimand : 16
Estimand name: backdoor16
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,guests)
### Estimand : 17
Estimand name: backdoor17
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes)
### Estimand : 18
Estimand name: backdoor18
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes)
### Estimand : 19
Estimand name: backdoor19
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay)
### Estimand : 20
Estimand name: backdoor20
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list)
### Estimand : 21
Estimand name: backdoor21
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,meal)
### Estimand : 22
Estimand name: backdoor22
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,guests)
### Estimand : 23
Estimand name: backdoor23
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes)
### Estimand : 24
Estimand name: backdoor24
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay)
### Estimand : 25
Estimand name: backdoor25
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list)
### Estimand : 26
Estimand name: backdoor26
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,meal)
### Estimand : 27
Estimand name: backdoor27
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,guests)
### Estimand : 28
Estimand name: backdoor28
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay)
### Estimand : 29
Estimand name: backdoor29
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 30
Estimand name: backdoor30
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,meal)
### Estimand : 31
Estimand name: backdoor31
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,guests)
### Estimand : 32
Estimand name: backdoor32
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 33
Estimand name: backdoor33
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,meal)
### Estimand : 34
Estimand name: backdoor34
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,guests)
### Estimand : 35
Estimand name: backdoor35
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,d
d[different_room_assigned]
ays_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,meal)
### Estimand : 36
Estimand name: backdoor36
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,d
d[different_room_assigned]
ays_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,guests)
### Estimand : 37
Estimand name: backdoor37
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,m
d[different_room_assigned]
eal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,meal,guests)
### Estimand : 38
Estimand name: backdoor38
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes)
### Estimand : 39
Estimand name: backdoor39
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes)
### Estimand : 40
Estimand name: backdoor40
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay)
### Estimand : 41
Estimand name: backdoor41
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list)
### Estimand : 42
Estimand name: backdoor42
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,meal)
### Estimand : 43
Estimand name: backdoor43
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,guests)
### Estimand : 44
Estimand name: backdoor44
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes)
### Estimand : 45
Estimand name: backdoor45
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay)
### Estimand : 46
Estimand name: backdoor46
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list)
### Estimand : 47
Estimand name: backdoor47
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,meal)
### Estimand : 48
Estimand name: backdoor48
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,guests)
### Estimand : 49
Estimand name: backdoor49
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay)
### Estimand : 50
Estimand name: backdoor50
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 51
Estimand name: backdoor51
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,meal)
### Estimand : 52
Estimand name: backdoor52
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,guests)
### Estimand : 53
Estimand name: backdoor53
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 54
Estimand name: backdoor54
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,meal)
### Estimand : 55
Estimand name: backdoor55
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,guests)
### Estimand : 56
Estimand name: backdoor56
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,meal)
### Estimand : 57
Estimand name: backdoor57
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,guests)
### Estimand : 58
Estimand name: backdoor58
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,meal,guests)
### Estimand : 59
Estimand name: backdoor59
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes)
### Estimand : 60
Estimand name: backdoor60
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay)
### Estimand : 61
Estimand name: backdoor61
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list)
### Estimand : 62
Estimand name: backdoor62
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,meal)
### Estimand : 63
Estimand name: backdoor63
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,guests)
### Estimand : 64
Estimand name: backdoor64
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay)
### Estimand : 65
Estimand name: backdoor65
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 66
Estimand name: backdoor66
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,meal)
### Estimand : 67
Estimand name: backdoor67
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,guests)
### Estimand : 68
Estimand name: backdoor68
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 69
Estimand name: backdoor69
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,meal)
### Estimand : 70
Estimand name: backdoor70
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,guests)
### Estimand : 71
Estimand name: backdoor71
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal)
### Estimand : 72
Estimand name: backdoor72
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,guests)
### Estimand : 73
Estimand name: backdoor73
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,meal,guests)
### Estimand : 74
Estimand name: backdoor74
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay)
### Estimand : 75
Estimand name: backdoor75
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 76
Estimand name: backdoor76
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,meal)
### Estimand : 77
Estimand name: backdoor77
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,guests)
### Estimand : 78
Estimand name: backdoor78
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 79
Estimand name: backdoor79
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,meal)
### Estimand : 80
Estimand name: backdoor80
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,guests)
### Estimand : 81
Estimand name: backdoor81
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,meal)
### Estimand : 82
Estimand name: backdoor82
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,guests)
### Estimand : 83
Estimand name: backdoor83
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,meal,guests)
### Estimand : 84
Estimand name: backdoor84
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 85
Estimand name: backdoor85
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,meal)
### Estimand : 86
Estimand name: backdoor86
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,guests)
### Estimand : 87
Estimand name: backdoor87
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 88
Estimand name: backdoor88
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 89
Estimand name: backdoor89
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,meal,guests)
### Estimand : 90
Estimand name: backdoor90
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 91
Estimand name: backdoor91
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 92
Estimand name: backdoor92
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,meal,guests)
### Estimand : 93
Estimand name: backdoor93
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,d
d[different_room_assigned]
ays_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 94
Estimand name: backdoor94
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes)
### Estimand : 95
Estimand name: backdoor95
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay)
### Estimand : 96
Estimand name: backdoor96
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list)
### Estimand : 97
Estimand name: backdoor97
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,meal)
### Estimand : 98
Estimand name: backdoor98
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,guests)
### Estimand : 99
Estimand name: backdoor99
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay)
### Estimand : 100
Estimand name: backdoor100
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting
_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 101
Estimand name: backdoor101
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,meal)
### Estimand : 102
Estimand name: backdoor102
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,guests)
### Estimand : 103
Estimand name: backdoor103
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_lis
t))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 104
Estimand name: backdoor104
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,meal)
### Estimand : 105
Estimand name: backdoor105
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,guests)
### Estimand : 106
Estimand name: backdoor106
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal)
### Estimand : 107
Estimand name: backdoor107
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,guests)
### Estimand : 108
Estimand name: backdoor108
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,meal,guests)
### Estimand : 109
Estimand name: backdoor109
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay)
### Estimand : 110
Estimand name: backdoor110
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 111
Estimand name: backdoor111
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,meal)
### Estimand : 112
Estimand name: backdoor112
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,guests)
### Estimand : 113
Estimand name: backdoor113
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 114
Estimand name: backdoor114
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,meal)
### Estimand : 115
Estimand name: backdoor115
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,guests)
### Estimand : 116
Estimand name: backdoor116
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,meal)
### Estimand : 117
Estimand name: backdoor117
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,guests)
### Estimand : 118
Estimand name: backdoor118
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,meal,guests)
### Estimand : 119
Estimand name: backdoor119
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 120
Estimand name: backdoor120
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,meal)
### Estimand : 121
Estimand name: backdoor121
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,guests)
### Estimand : 122
Estimand name: backdoor122
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 123
Estimand name: backdoor123
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 124
Estimand name: backdoor124
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,meal,guests)
### Estimand : 125
Estimand name: backdoor125
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 126
Estimand name: backdoor126
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 127
Estimand name: backdoor127
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,meal,guests)
### Estimand : 128
Estimand name: backdoor128
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 129
Estimand name: backdoor129
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay)
### Estimand : 130
Estimand name: backdoor130
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 131
Estimand name: backdoor131
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,meal)
### Estimand : 132
Estimand name: backdoor132
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,guests)
### Estimand : 133
Estimand name: backdoor133
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 134
Estimand name: backdoor134
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,meal)
### Estimand : 135
Estimand name: backdoor135
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,guests)
### Estimand : 136
Estimand name: backdoor136
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal)
### Estimand : 137
Estimand name: backdoor137
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,guests)
### Estimand : 138
Estimand name: backdoor138
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,meal,guests)
### Estimand : 139
Estimand name: backdoor139
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 140
Estimand name: backdoor140
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal)
### Estimand : 141
Estimand name: backdoor141
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,guests)
### Estimand : 142
Estimand name: backdoor142
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 143
Estimand name: backdoor143
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 144
Estimand name: backdoor144
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,meal,guests)
### Estimand : 145
Estimand name: backdoor145
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 146
Estimand name: backdoor146
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 147
Estimand name: backdoor147
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,meal,guests)
### Estimand : 148
Estimand name: backdoor148
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 149
Estimand name: backdoor149
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 150
Estimand name: backdoor150
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,meal)
### Estimand : 151
Estimand name: backdoor151
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,guests)
### Estimand : 152
Estimand name: backdoor152
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 153
Estimand name: backdoor153
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 154
Estimand name: backdoor154
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,meal,guests)
### Estimand : 155
Estimand name: backdoor155
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 156
Estimand name: backdoor156
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 157
Estimand name: backdoor157
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,meal,guests)
### Estimand : 158
Estimand name: backdoor158
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 159
Estimand name: backdoor159
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 160
Estimand name: backdoor160
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 161
Estimand name: backdoor161
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 162
Estimand name: backdoor162
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 163
Estimand name: backdoor163
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,booking_changes,t
d[different_room_assigned]
otal_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 164
Estimand name: backdoor164
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay)
### Estimand : 165
Estimand name: backdoor165
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in
_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list)
### Estimand : 166
Estimand name: backdoor166
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,meal)
### Estimand : 167
Estimand name: backdoor167
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,guests)
)
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,guests)
### Estimand : 168
Estimand name: backdoor168
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_wai
ting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 169
Estimand name: backdoor169
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,meal)
### Estimand : 170
Estimand name: backdoor170
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,guests)
### Estimand : 171
Estimand name: backdoor171
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,m
eal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal)
### Estimand : 172
Estimand name: backdoor172
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,g
uests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,guests)
### Estimand : 173
Estimand name: backdoor173
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,meal,guests)
### Estimand : 174
Estimand name: backdoor174
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days
_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 175
Estimand name: backdoor175
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal
))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal)
### Estimand : 176
Estimand name: backdoor176
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,gues
ts))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,guests)
### Estimand : 177
Estimand name: backdoor177
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting
_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 178
Estimand name: backdoor178
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting
_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 179
Estimand name: backdoor179
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,meal,guests)
### Estimand : 180
Estimand name: backdoor180
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_lis
t,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 181
Estimand name: backdoor181
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_lis
t,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 182
Estimand name: backdoor182
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,meal,guests)
### Estimand : 183
Estimand name: backdoor183
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,gues
ts))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 184
Estimand name: backdoor184
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 185
Estimand name: backdoor185
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,meal)
### Estimand : 186
Estimand name: backdoor186
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,guests)
### Estimand : 187
Estimand name: backdoor187
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 188
Estimand name: backdoor188
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 189
Estimand name: backdoor189
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,meal,guests)
### Estimand : 190
Estimand name: backdoor190
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 191
Estimand name: backdoor191
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 192
Estimand name: backdoor192
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,meal,guests)
### Estimand : 193
Estimand name: backdoor193
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 194
Estimand name: backdoor194
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 195
Estimand name: backdoor195
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 196
Estimand name: backdoor196
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 197
Estimand name: backdoor197
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 198
Estimand name: backdoor198
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,booking_changes,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 199
Estimand name: backdoor199
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waitin
g_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 200
Estimand name: backdoor200
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal)
### Estimand : 201
Estimand name: backdoor201
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,guests)
### Estimand : 202
Estimand name: backdoor202
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal
))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 203
Estimand name: backdoor203
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,gues
ts))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 204
Estimand name: backdoor204
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,guests)
### Estimand : 205
Estimand name: backdoor205
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 206
Estimand name: backdoor206
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 207
Estimand name: backdoor207
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,guests)
### Estimand : 208
Estimand name: backdoor208
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 209
Estimand name: backdoor209
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,m
eal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 210
Estimand name: backdoor210
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,g
uests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 211
Estimand name: backdoor211
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 212
Estimand name: backdoor212
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,guests)
)
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 213
Estimand name: backdoor213
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 214
Estimand name: backdoor214
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 215
Estimand name: backdoor215
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 216
Estimand name: backdoor216
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 217
Estimand name: backdoor217
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 218
Estimand name: backdoor218
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,booking_c
d[different_room_assigned]
hanges,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 219
Estimand name: backdoor219
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,market_segment,bo
d[different_room_assigned]
oking_changes,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 220
Estimand name: backdoor220
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,days_in_waiting_list))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list)
### Estimand : 221
Estimand name: backdoor221
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal)
### Estimand : 222
Estimand name: backdoor222
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,guests)
### Estimand : 223
Estimand name: backdoor223
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in
_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal)
### Estimand : 224
Estimand name: backdoor224
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in
_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,guests)
### Estimand : 225
Estimand name: backdoor225
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,gu
ests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,meal,guests)
### Estimand : 226
Estimand name: backdoor226
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_wai
ting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 227
Estimand name: backdoor227
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_wai
ting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 228
Estimand name: backdoor228
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,guests
))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,meal,guests)
### Estimand : 229
Estimand name: backdoor229
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,m
eal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 230
Estimand name: backdoor230
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days
_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 231
Estimand name: backdoor231
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days
_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 232
Estimand name: backdoor232
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal
,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 233
Estimand name: backdoor233
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting
_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 234
Estimand name: backdoor234
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_lis
t,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 235
Estimand name: backdoor235
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 236
Estimand name: backdoor236
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests
))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 237
Estimand name: backdoor237
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 238
Estimand name: backdoor238
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 239
Estimand name: backdoor239
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,booking_changes,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 240
Estimand name: backdoor240
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 241
Estimand name: backdoor241
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waitin
g_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 242
Estimand name: backdoor242
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waitin
g_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 243
Estimand name: backdoor243
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 244
Estimand name: backdoor244
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal
,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 245
Estimand name: backdoor245
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,gue
sts))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 246
Estimand name: backdoor246
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,m
eal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 247
Estimand name: backdoor247
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,country,market_se
d[different_room_assigned]
gment,booking_changes,total_stay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 248
Estimand name: backdoor248
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,days_in_waiting_list,meal))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal)
### Estimand : 249
Estimand name: backdoor249
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,days_in_waiting_list,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,guests)
### Estimand : 250
Estimand name: backdoor250
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,meal,guests)
### Estimand : 251
Estimand name: backdoor251
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in
_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,days_in_waiting_list,meal,guests)
### Estimand : 252
Estimand name: backdoor252
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_wai
ting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 253
Estimand name: backdoor253
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days
_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 254
Estimand name: backdoor254
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,g
uests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 255
Estimand name: backdoor255
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,previous_bookings
d[different_room_assigned]
_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waitin
g_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 256
Estimand name: backdoor256 (Default)
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|lead_time,is_repeated_guest
d[different_room_assigned]
,previous_bookings_not_canceled,country,market_segment,booking_changes,total_s
tay,days_in_waiting_list,meal,guests))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests,U) = P(is_canceled|different_room_assigned,lead_time,is_repeated_guest,previous_bookings_not_canceled,country,market_segment,booking_changes,total_stay,days_in_waiting_list,meal,guests)
### Estimand : 257
Estimand name: iv
No such variable found!
### Estimand : 258
Estimand name: frontdoor
No such variable found!
Step-3. Estimate the identified estimand
[15]:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification",target_units="ate")
# ATE = Average Treatment Effect
# ATT = Average Treatment Effect on Treated (i.e. those who were assigned a different room)
# ATC = Average Treatment Effect on Control (i.e. those who were not assigned a different room)
print(estimate)
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
*** Causal Estimate ***
## Identified estimand
Estimand type: nonparametric-ate
## Realized estimand
b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
Target units: ate
## Estimate
Mean value: -0.33682918938420675
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
Step-4. Refute results
Note that the causal part does not come from data. It comes from your assumptions that lead to identification. Data is simply used for statistical estimation. Thus it becomes critical to verify whether our assumptions were even correct in the first step or not!
What happens when another common cause exists? What happens when the treatment itself was placebo?
Method-1
Radom Common Cause:- Adds randomly drawn covariates to data and re-runs the analysis to see if the causal estimate changes or not. If our assumption was originally correct then the causal estimate shouldn’t change by much.
[16]:
refute1_results=model.refute_estimate(identified_estimand, estimate,
method_name="random_common_cause")
print(refute1_results)
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests+w_random
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
Refute: Add a Random Common Cause
Estimated effect:-0.33682918938420675
New effect:-0.336156826783791
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
Method-2
Placebo Treatment Refuter:- Randomly assigns any covariate as a treatment and re-runs the analysis. If our assumptions were correct then this newly found out estimate should go to 0.
[17]:
refute2_results=model.refute_estimate(identified_estimand, estimate,
method_name="placebo_treatment_refuter")
print(refute2_results)
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Refutation over 100 simulated datasets of Random Data treatment
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Using a Binomial Distribution with 1 trials and 0.5 probability of success
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~placebo+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.placebo_treatment_refuter:Making use of Bootstrap as we have more than 100 examples.
Note: The greater the number of examples, the more accurate are the confidence estimates
Refute: Use a Placebo Treatment
Estimated effect:-0.33682918938420675
New effect:0.00021368335134707773
p value:0.49
Method-3
Data Subset Refuter:- Creates subsets of the data(similar to cross-validation) and checks whether the causal estimates vary across subsets. If our assumptions were correct there shouldn’t be much variation.
[18]:
refute3_results=model.refute_estimate(identified_estimand, estimate,
method_name="data_subset_refuter")
print(refute3_results)
INFO:dowhy.causal_refuters.data_subset_refuter:Refutation over 0.8 simulated datasets of size 95508.8 each
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_estimator:INFO: Using Propensity Score Stratification Estimator
INFO:dowhy.causal_estimator:b: is_canceled~different_room_assigned+lead_time+is_repeated_guest+previous_bookings_not_canceled+country+market_segment+booking_changes+total_stay+days_in_waiting_list+meal+guests
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
/home/amit/py-envs/env3.8/lib/python3.8/site-packages/pandas/core/computation/expressions.py:203: UserWarning: evaluating in Python space because the '*' operator is not supported by numexpr for the bool dtype, use '&' instead
warnings.warn(
INFO:dowhy.causal_refuters.data_subset_refuter:Making use of Bootstrap as we have more than 100 examples.
Note: The greater the number of examples, the more accurate are the confidence estimates
Refute: Use a subset of data
Estimated effect:-0.33682918938420675
New effect:-0.33645145863692627
p value:0.43
We can see that our estimate passes all three refutation tests. This does not prove its correctness, but it increases confidence in the estimate.
Comparing Results with XGBoost Feature Importance
We now know the effect of assigning a different room is 36 percentage points, so it might be a good exercise to compare results with feature importance obtained using a model offering high predictive accuracy on this dataset.
We choose XGBoost as the model as it offers a fairly high predictive accuracy on this dataset. The plot_importance function of XGBoost is used to calculate feature importance. Contrary to our analysis using DoWhy, it is observed that Different_room_assigned attains a relatively low importance score.
[35]:
# plot feature importance using built-in function
from xgboost import XGBClassifier
from xgboost import plot_importance
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from matplotlib import pyplot
# split data into X and y
X = dataset_copy
y = dataset_copy['is_canceled']
X = X.drop(['is_canceled'],axis=1)
# One-Hot Encode the dataset
X = pd.get_dummies(X)
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=26)
# fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data and evaluate
y_pred = model.predict(X_test)
predictions = [int(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
print(classification_report(y_test, predictions))
Accuracy: 86.90%
precision recall f1-score support
False 0.88 0.92 0.90 15001
True 0.85 0.79 0.82 8877
accuracy 0.87 23878
macro avg 0.86 0.85 0.86 23878
weighted avg 0.87 0.87 0.87 23878
The feature importance plotted below uses weight to rank features. Here weight is the number of times a feature appears in a tree
[36]:
# plot feature importance
plot_importance(model,max_num_features=20)
pyplot.show()

[37]:
# Execute this code to hide all warnings
from IPython.display import HTML
HTML('''<script>
code_show_err=false;
function code_toggle_err() {
if (code_show_err){
$('div.output_stderr').hide();
} else {
$('div.output_stderr').show();
}
code_show_err = !code_show_err
}
$( document ).ready(code_toggle_err);
</script>
To toggle on/off output_stderr, click <a href="javascript:code_toggle_err()">here</a>.''')
[37]: